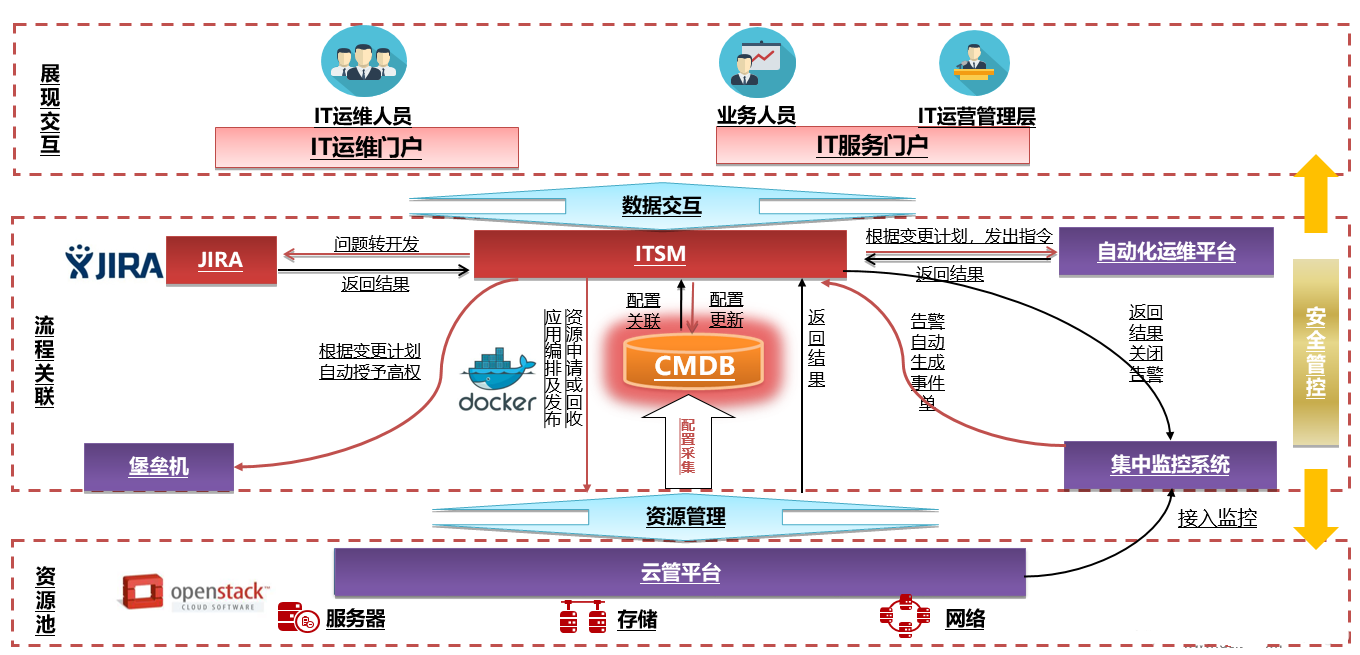
IT运维管理(IT Operations Management)就像是企业的IT系统管家,负责让整个技术架构平稳运行。想象一下,一个公司有上百台服务器、网络设备、各种软件系统,这些都需要7×24小时稳定工作。IT运维团队就是确保这些"数字基础设施"不宕机、不出错的幕后英雄。ServiceHot作为ITSM 2.0倡导者,将传统运维升级为更智能的运营模式,通过自动化工具实时监控系统健康状态,就像给IT系统装上了"智能体检仪"。现代运维早已不是简单的修电脑、重启服务器,而是包含配置管理、容量规划、变更控制等专业领域。比如当系统流量突然激增时,运维平能自动扩容云服务器;当发现安全漏洞时,可以一键下发补丁。ServiceHot ITSOM平台正是把这些复杂场景变成可视化、可量化的管理流程,让运维从"救火队"转型为"预防专家"。
it运维管理年终工作总结
又到一年盘点时,IT运维人的年终总结往往写满惊心动魄的故事。今年我们通过ServiceHot运维平台处理了3287个告警事件,平均响应时间从去年的47分钟缩短到12分钟。最惊险的是双十一期间,电商平台每秒订单量突破5万笔,但基于ServiceHot的智能容量预测功能,我们提前两周就完成了服务器集群扩容。在成本控制方面,通过资源利用率分析关停了137台闲置虚拟机,节省了28%的云计算开支。值得骄傲的是,今年首次实现全年核心系统零重大故障,这要归功于ServiceHot的故障自愈功能——有次数据库主节点宕机,系统在90秒内就自动完成了切换。当然也有教训,某次变更忘记在测试环境验证,直接导致生产环境服务中断15分钟。现在我们都养成了用ServiceHot变更管理模块走标准化流程的习惯。展望明年,计划将AIOps功能深度应用到日志分析中,让机器帮我们发现更多潜在风险。
浅谈事件管理
事件管理是IT运维的"急诊科",处理不好随时可能演变成业务灾难。在金融行业有个经典案例:某证券交易系统突然出现延时,传统监控只能看到服务器CPU飙高,但通过ServiceHot的事件关联分析,发现是某个微服务调用Redis时产生了死锁。这就是现代事件管理的精髓——不仅要看到现象,更要定位根因。我们常把事件分为"尖叫事件"(比如官网崩溃)和"沉默事件"(缓慢的内存泄漏),后者往往更危险。ServiceHot平台的事件风暴抑制功能特别实用,上周有个网络抖动原本会触发2000多条告警,系统自动归并成3个有效事件单。还有个反常识的发现:60%的严重事件其实由小变更引发,所以我们现在严格执行"变更-监控-回滚"的闭环管理。最近正在试验用ServiceHot的预测性维护功能,通过对历史事件的学习,系统已经能提前4小时预测到磁盘写满风险,这让运维真正有了"预见未来"的能力。